Looking for the Korean version? Read this post in Korean →
While Solar Pro 2 set the standard for production-ready LLMs with a focus on efficiency and stability suitable for enterprise deployment, Solar Pro 3 builds on that foundation by taking reasoning accuracy and instruction-following quality one step further.
This release is not simply about increasing raw performance. Solar Pro 3 is designed to improve response quality while maintaining the same API interface, throughput, and serving behavior. Teams already using Solar Pro 2 can switch models without changing request formats, workflows, or system configurations—and immediately experience higher-quality responses under the same operating conditions.
What’s changed from Solar Pro 2
Solar Pro 3 delivers meaningful performance improvements in areas closely tied to real user interactions, while maintaining similar throughput (TPS) and cost characteristics as Solar Pro 2. The model shows particularly strong gains in instruction-following capability with a 52% improvement (IFBench 55.78) and complex reasoning tasks with a 30% improvement (Arena Hard v2 62.5)—both critical areas that directly impact production quality.
The chart below compares Solar Pro 2 and Solar Pro 3 under identical conditions. Each metric represents either a representative benchmark score or an average across multiple benchmarks, serving as indicators of the reasoning quality differences users can expect when calling the API.
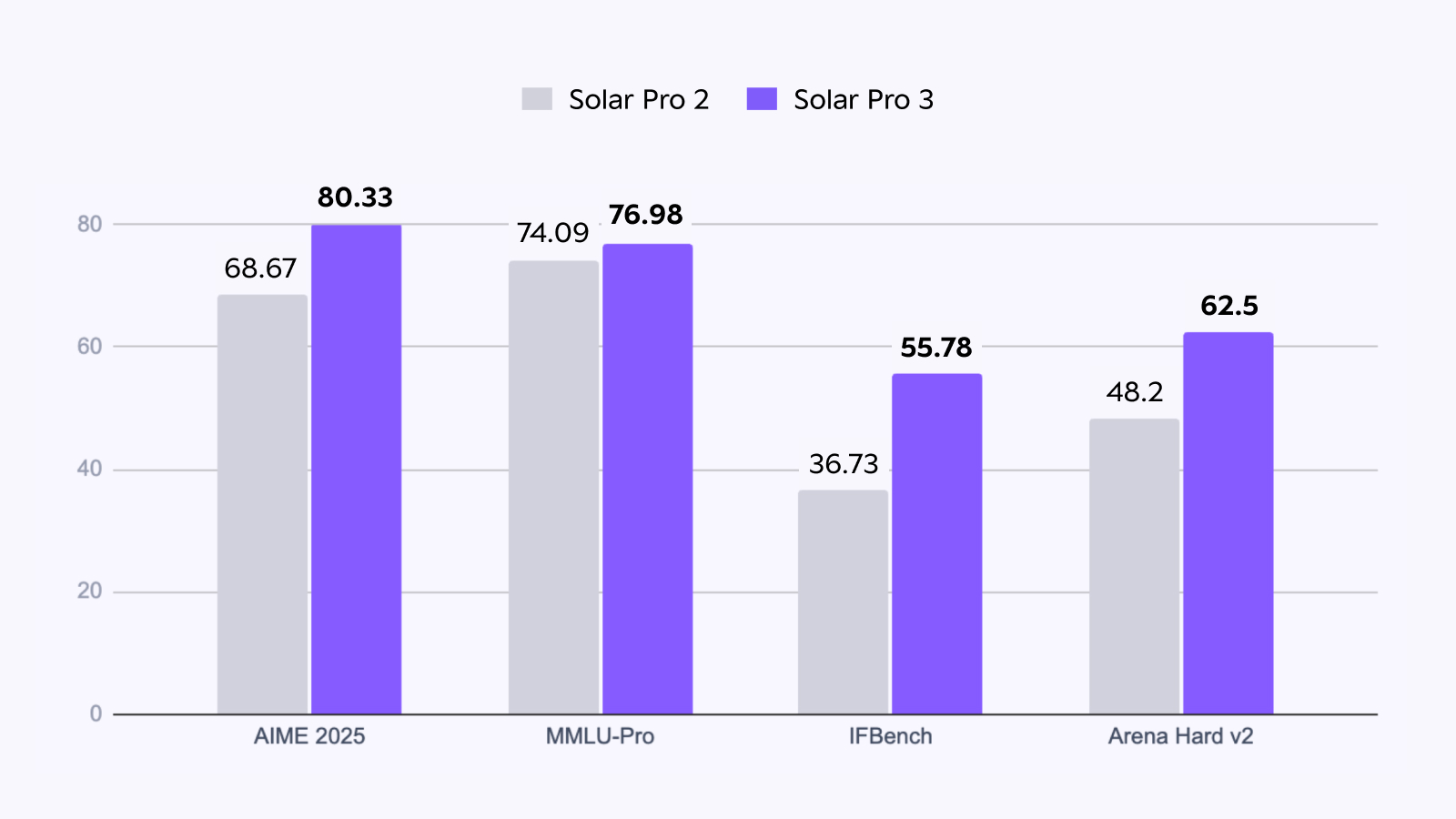
Solar Pro 3 delivers more accurate and stable responses than Solar Pro 2 across instruction-following and reasoning-focused benchmarks, while preserving the same serving efficiency.
Across instruction following, preference alignment, and reasoning-focused benchmarks, Solar Pro 3 shows consistent gains over Solar Pro 2, delivering more stable and accurate responses under the same serving conditions.
Performance improvements driven by real-world usage
The performance gains in Solar Pro 3 are not the result of optimizing for a single benchmark. They reflect design choices informed by limitations repeatedly observed in production environments. The model is optimized to improve response consistency and accuracy for tasks that require multi-step reasoning, handle subtle instruction differences, or involve complex preference judgments.
In math and logical reasoning tasks, Solar Pro 3 records meaningful improvements over Solar Pro 2. Instruction-following benchmarks also show clear gains. These results indicate more than higher scores—they reflect a stronger ability to correctly interpret user intent and follow tasks through to completion.
Preserving efficiency while expanding experience
Solar Pro 3 is designed to retain the expressive power of a large model while delivering the same serving efficiency and response latency as Solar Pro 2. This minimizes the typical trade-off where performance improvements lead directly to higher operating costs.
With a broader and deeper training foundation, Solar Pro 3 improves response quality across general knowledge, specialized domains, and complex reasoning tasks. Its core goal is to better capture user intent and context in both Korean and English, providing more reliable and accurate outputs in real applications.
Built with enterprise deployment in mind
Solar Pro 3 is designed for teams deploying large language models in real services. It prioritizes compatibility with existing systems, stable throughput, and predictable operating costs, while improving reasoning accuracy and response quality.
The model is built to support enterprise-grade scenarios—including complex queries, multi-step reasoning workflows, and fine-grained interpretation of user intent—without compromising reliability in production environments.
Experience Solar Pro 3 today
Solar Pro 3 is currently available via the Upstage Console as an API, allowing teams to test the model directly in real service environments. It is also accessible through yupp.ai, OpenRouter and BizRouter. Existing Solar Pro 2 users can switch to Solar Pro 3 without any configuration changes and run it under the same workloads.
Solar Pro 3 is available for free until March 2, 2026, 23:59 UTC. Experience the improved reasoning quality of Solar Pro 3 in your production workloads.
- Try it in the Playground ↗︎
- Use the Solar Pro 3 API in Upstage Console ↗︎
- See documentation for full specs ↗︎
.avif)