

Solar Pro 3 is the latest update to Solar Pro, Upstage's large language model.Updated in March 2026, Solar Pro 3 delivers meaningful gains across every category compared to Solar Pro 2 — roughly doubling agentic benchmark scores, advancing deep reasoning and instruction following, and raising Korean-language performance to reasoning-level quality. At the core of these improvements is SnapPO, Upstage's proprietary reinforcement learning technique. All gains are delivered at the same API interface and processing speed.
2× Agentic Performance
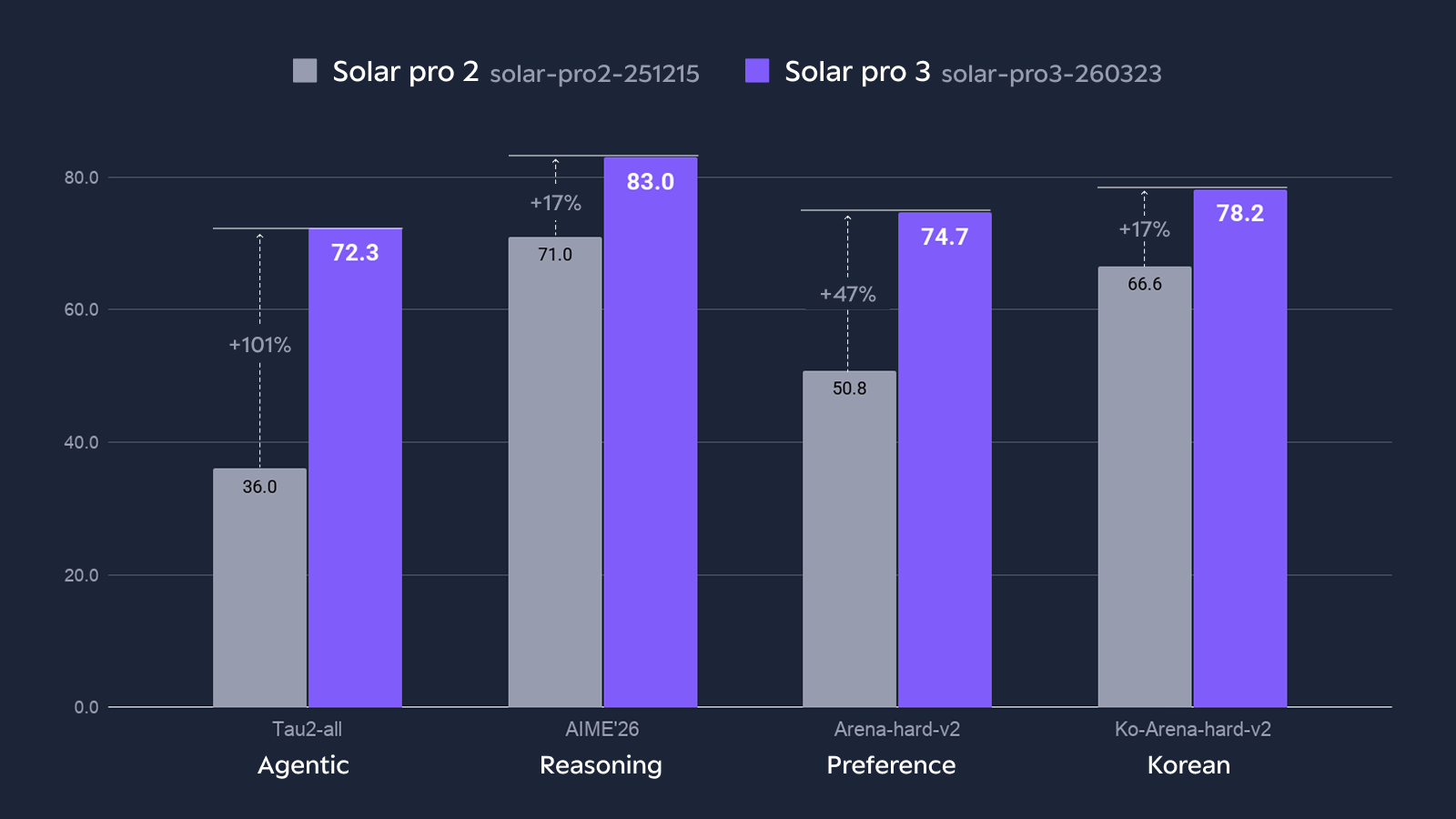
On Tau2-all, the comprehensive agentic evaluation, Solar Pro 3 reaches 72.3 — well above Solar Pro 2's 36.0. Code agents (SWE Bench) and terminal workflows (Terminal Bench 2) show the same direction of improvement.
2× Agentic benchmark improvement over Solar Pro 2: Tau2-all 72.3 (vs 36.0) · SWE Bench 28.6 (vs 14.5) · Terminal Bench 2 10.1 (vs 2.2)
These improvements are not the result of optimizing for any single benchmark. They reflect design decisions informed by limitations repeatedly observed in production — individual tool calls succeed but end-to-end workflows fail to complete.
What Reasoning Changed
Improving agentic performance is not just about tuning tool calls at the surface level. It requires the ability to maintain a coherent plan across multiple steps, catch errors before they accumulate, and make sound judgments when context is incomplete or tool outputs are ambiguous.
Solar Pro 3 applies SnapPO, Upstage's proprietary reinforcement learning framework, to meaningfully strengthen step-by-step reasoning. SnapPO is designed so that each stage of the training process can run and compose independently, enabling efficient simultaneous improvement of reasoning across diverse domains — math, code, and agentic tasks. It is an in-house technique developed through the Solar Open model research program; for a deeper look at its design and training methodology, see the technical report.
The improvement is confirmed on math and science benchmarks that demand exactly the same kind of sustained, multi-step thinking.
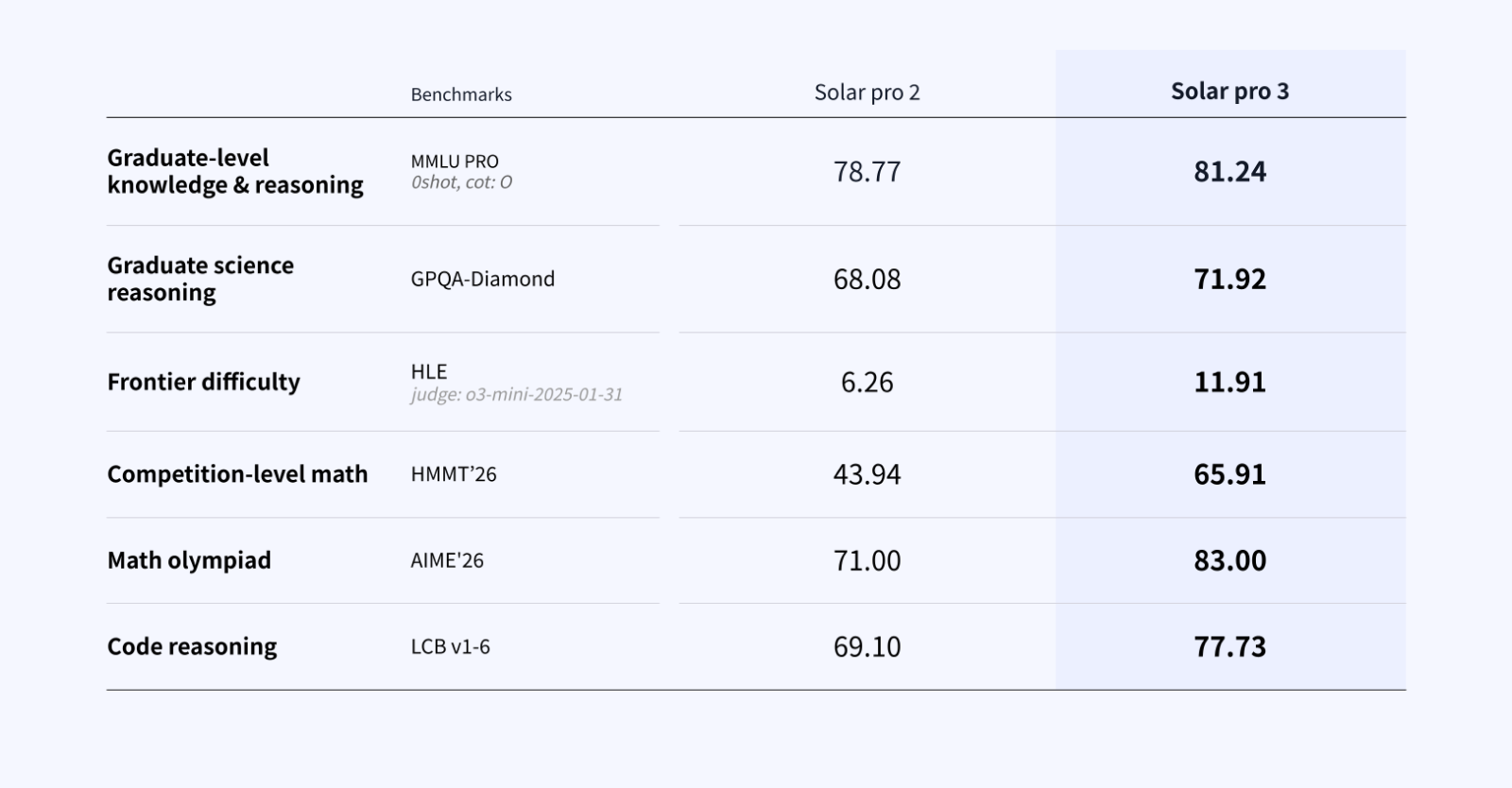
While these benchmarks are not agentic evaluations, the cognitive demands they impose — long reasoning chains, zero tolerance for error accumulation, the ability to backtrack when initial assumptions prove wrong — are similar to agentic workflows. Models that handle these tasks well tend to be more reliable in production agent pipelines.
Better Responses, Precise Instruction Following
In direct comparisons, users consistently preferred Solar Pro 3's outputs over Pro 2's. The model more accurately grasps user intent and generates more appropriate responses to nuanced instruction differences. Instruction following shows equally meaningful progress — this goes beyond higher scores to mean the model understands user requests more precisely and follows through to resolution.
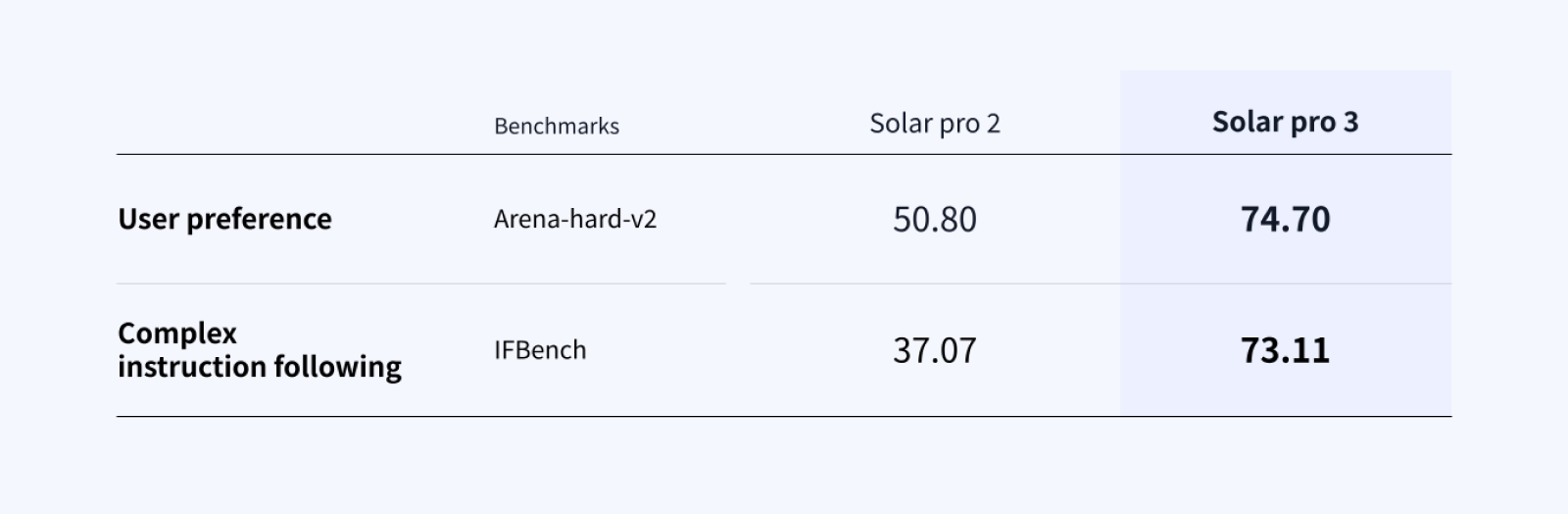
In agentic tasks, where instructions are inherently incomplete, this capability directly determines workflow reliability.
Korean: More Natural, Less Lost in Translation
One of Solar's differentiators is sustained investment in Korean language quality. On Ko-Arena-hard-v2, Solar Pro 3 reaches 78.2, up from Solar Pro 2's 66.6. The model now generates more natural Korean responses without the quality gap typically seen relative to English, and for teams running agents in Korean-language work environments, this translates directly into more reliable workflows.
Same Cost, Predictable Operations
Solar Pro 3 is built on a Mixture-of-Experts architecture with 102B total parameters, activating only 12B per token at inference time. Performance improves while maintaining the same API interface, throughput (TPS), and serving behavior as Solar Pro 2 — minimizing the typical trade-off where performance gains lead to cost increases.
At the operations stage, what matters is not peak performance but predictability — whether pipeline behavior remains stable across version updates, whether accuracy holds in Korean-language work environments, and whether serving costs stay within controllable bounds. Solar Pro 3's MoE architecture and Solar Pro 2-compatible design are choices made to meet these conditions while raising the performance ceiling. For detailed pricing, see the pricing page.
Try Solar Pro 3 Now
Solar Pro 3 is available through the Upstage Console as an API, ready for testing in real service environments. Existing Solar Pro 2 users can start using Solar Pro 3 immediately with no configuration changes.
Solar Pro 3 is also available on OpenRouter. Billions of tokens have already been processed through OpenRouter since launch in January.
Full Benchmark Details
Solar Pro 2 (solar-pro2-251215), Solar Pro 3 (solar-pro3-260323)
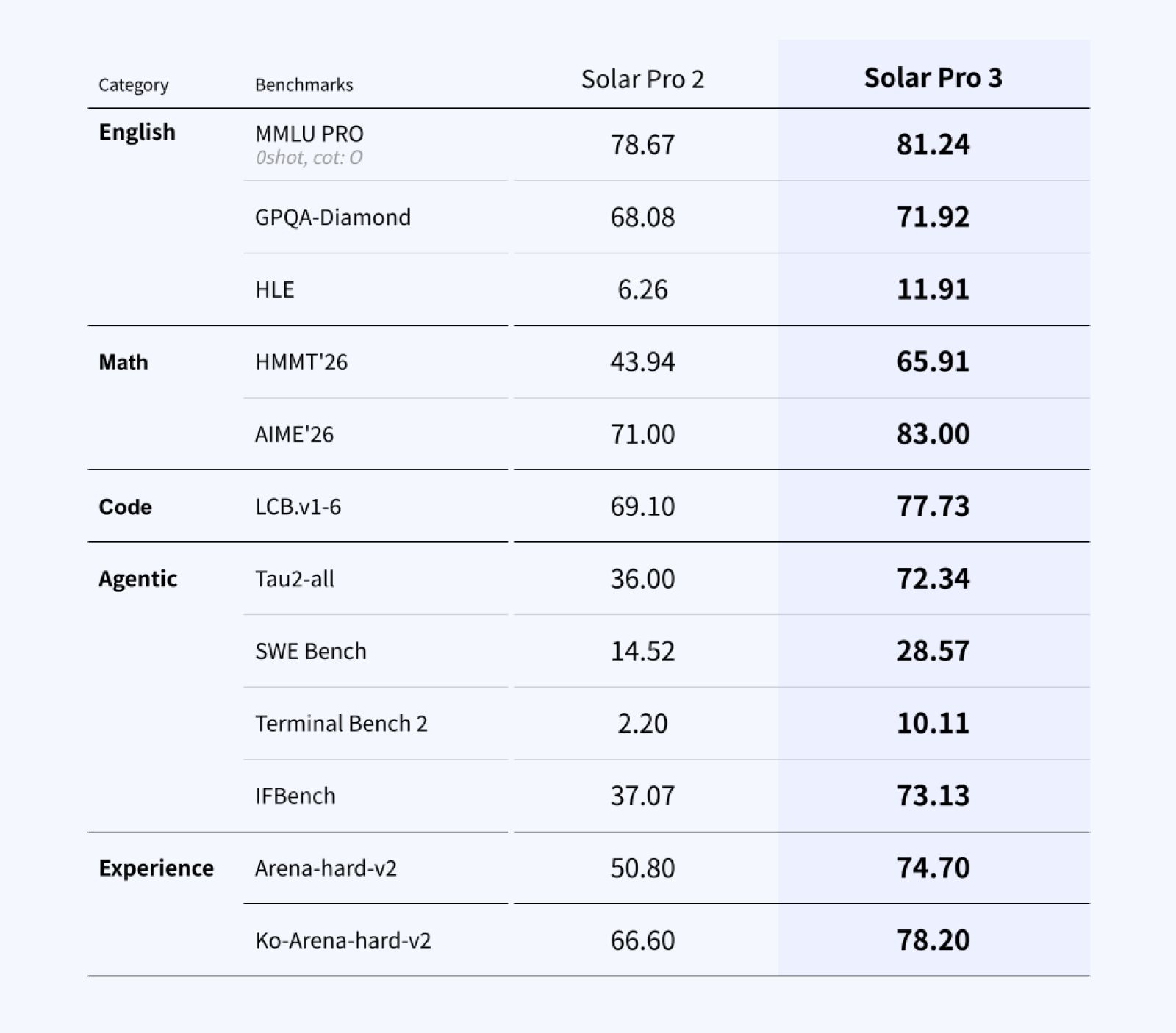
Benchmarks measured as of March 2026, following each benchmark's official evaluation protocol.




