

Upstageでは、現在、Information ExtractのPlaygroundをUpstage Studioで公開しています。既に先行してLaunchしている北米市場を始めとする海外のケースでは、ウェイトリストはすぐに埋まり、多くの開発者が保険書類、スキャンデータ、複数ページにわたるテーブルなど、実際の業務文書でテストを行いました。
こうした初期トラフィックを通じて、スキーマの整合性の確保やレイアウト処理の改善、バッチ処理性能の向上を重ねてきました。
現在、Information Extract は本番運用に対応した REST API として提供されています。非構造の PDF を、スキーマに準拠した構造化 JSON へ変換します。学習やテンプレートの作成、プロンプト調整は不要です。
Information Extractの特徴
- ゼロトレーニング抽出:テンプレートもファインチューニングも不要で、あらゆる文書に対応
- スキーマ準拠の出力:型、ネスト構造、必須フィールドを含む定義済みスキーマに基づき、構造化JSONを返却
- レイアウト理解:テーブル、チェックボックス、複数ページのレイアウト、回転したコンテンツなども高い精度で処理
- ページ単位の定額課金:トークン数やコンテンツの複雑さに依存しない、予測可能な料金体系
文書からJSONへ ― 1回のAPI呼び出しで完結
Information Extract は、レイアウトが複雑な PDF を、スキーマに準拠したクリーンな構造化 JSON に変換します。テンプレートやスクリプトは必要ありません。
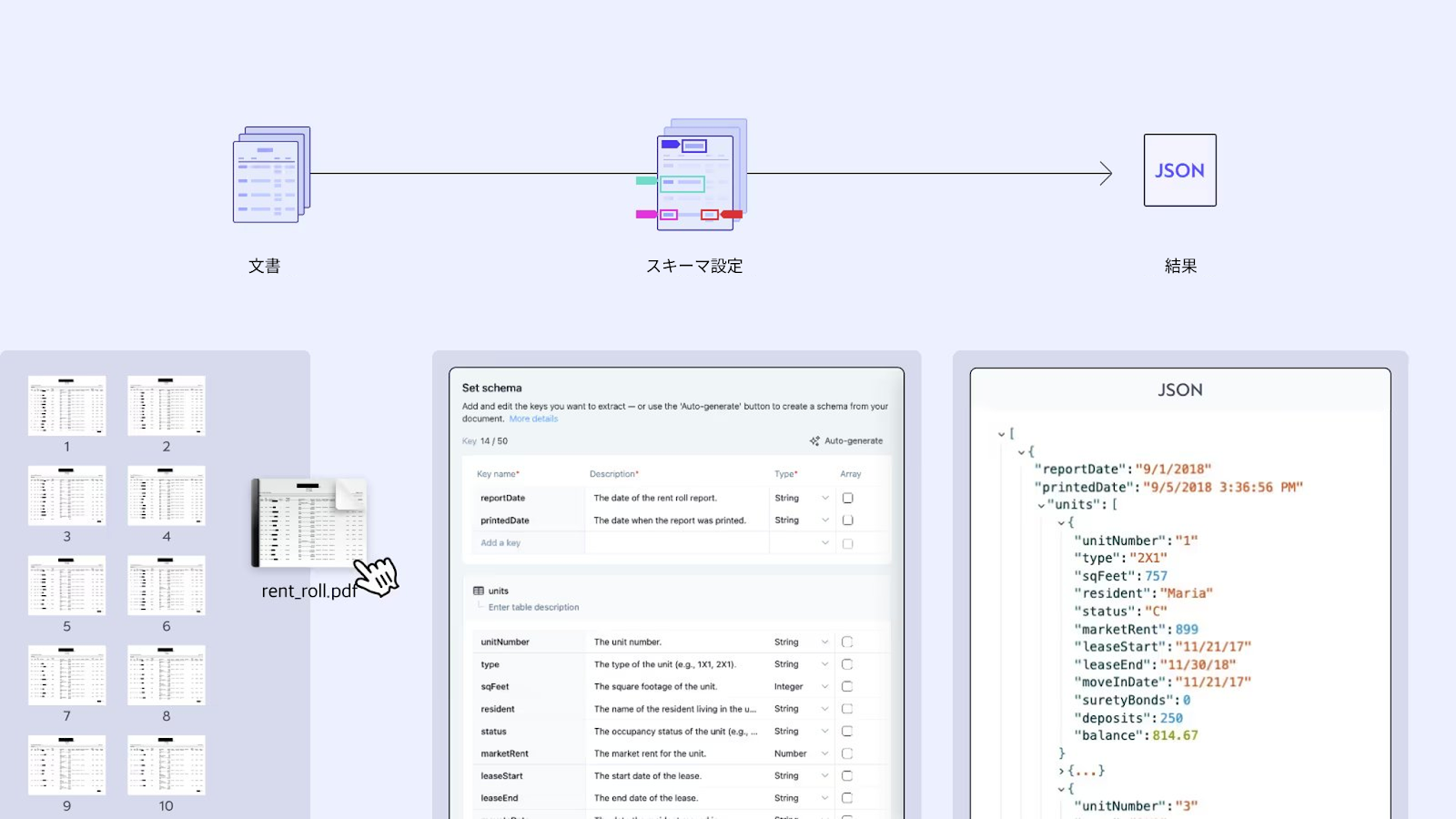
この例では、複数ページにわたる賃貸台帳の PDF を構造化 JSON に変換しています。各行は、賃料、保証金、割引、駐車場料金などのフィールドにマッピングされます。テンプレートやカスタムスクリプトは一切使用していません。
スキーマを指定して1回の呼び出しで抽出する方法
# スキーマを使用したInformation Extractリクエスト
extraction_response = client.chat.completions.create(
model="information-extract",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{base64_data}"}
}
]
}
],
response_format={
"type": "json_schema",
"json_schema": {
"name": "document_schema",
"schema": {
"type": "object",
"properties": {
"bank_name": {
"type": "string",
"description": "The name of bank in bank statement"
}
}
}
}
}
)
今すぐ利用可能
- Upstage Console:ワークスペースを作成すると、10ドル分の無料クレジットが付与されます。
アプリケーションに文書理解の力を。 Information Extract APIで構築を始めましょう。



.png)
