
近年、生成AIは実業務の中に浸透し、「AIを用いた業務改善」は特別なものではなくなりました。一方で、実務での活用にはまだ課題も残っています。
- 多くの生成AI(LLM)はテキスト情報を前提としている
- 画像を扱える生成AI(VLM)はコストが高い
- 業務ドキュメントには、コピー・スキャンなどテキスト化されていない資料が多い
これらのギャップにより、生成AIを業務にうまく組み込めていないケースも少なくありません。
本ブログでは、業務ドキュメントを 「AIが読みやすい形」に変換することで、生成AIがどのような処理・活用が可能になるのかを、具体例とともに説明していきます。

この記事はこんな方におすすめ
- 契約書・申請書・見積書など、ドキュメント処理を自動化したいエンジニア
- PythonとLLM APIに触れたことがあり、「Document AI × LLM × 評価」をどう組み合わせるか知りたい方
- UpstageのDocument AIやWeaveに興味があり、まずは試しながら理解したい方
「Upstage DP x Syn Proを用いたドキュメント作業効率化シリーズ(with Weave)」を読み終えるとできるようになること
- Upstage Document Parse (DP) を使って、PDFやスキャン文書をLLMが扱いやすい構造化データ(HTML / Markdown)に変換できる
- Syn Pro(日本語特化 LLM) を活用し、 要約・項目抽出など のパイプラインを構築できる
- Weights & Biases Weaveを用いて、パイプライン全体のTrace(処理ステップの可視化) とEvaluation(自前テストデータによる自動評価)を回せるようになる
参考:GitHubリポジトリ
fc_2025_upstage_handson(Fully Connected 2025 Tokyo ハンズオン用)
1. はじめに:なぜ「Document AI × LLM」が必要か
日本企業の現場では、いまだに紙・PDFベースの処理が大量にあります。
- 毎月、同じような申請書や見積書を“目で見て転記”している
- LLM / RAGを導入したが、紙データ → テキスト化の前処理が詰まっている
- 帳票のレイアウトが複雑で、通常の OCRではうまく扱えない
生成AIサービスが普及しても、現場にあるデータの多くは、
- 紙
- スキャンPDF
- 表・図・段組を含む複雑帳票
といった 「そのままでは LLM が理解しづらい非構造データ」です。
そこで本シリーズでは:
- DP:ドキュメント構造化・OCR
- Syn Pro:日本語 LLM による要約・抽出・質問対応
- Weave:Trace / Evaluationによる可視化・評価
を組み合わせ、「きちんと可視化&評価できるドキュメント処理パイプライン」 の構築を進めていきます。
2. Upstage Document Parse (DP) の役割
Upstage Document Parse(DP)は、PDFや画像のような非構造ドキュメントを構造化データへ変換します。
具体的には、
- PDF / スキャン画像 / 表・段組を含むドキュメントを対象に
- 段落・見出し・表などのレイアウトを保持した状態で
- HTML / Markdown と言ったLLMが理解しやすい形式へ変換
を実施し、OCR(ドキュメントに含まれる文字情報を抽出)だけでなく、テーブル・グラフなどの情報抽出やその構造化を行います。
これにより LLMには以下の情報が伝わります:
- どこが見出しか
- どこが表か
- どんなColumn / Rowがあるか
- どこにチャートがあり、その意味は何か
そのため、構造を理解したうえで要約・抽出・質問対応ができるようになります。
Document AIの重要性については、Zenn記事「Document AI が生成AI活用のカギ」にも詳しい解説があります。
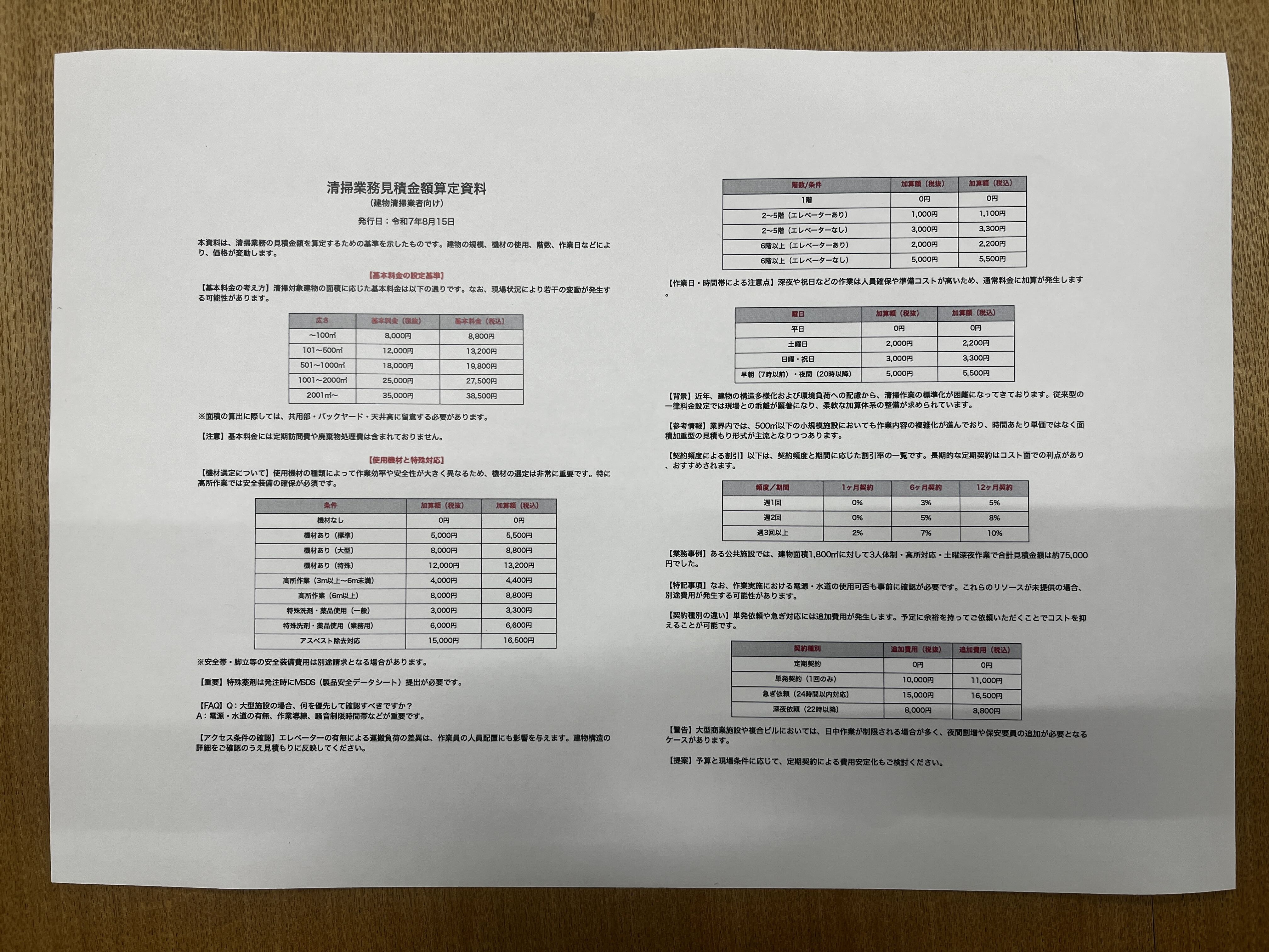
(例)2段落 + 複数表を含んだ「清掃見積もり概要ドキュメント」の構造化
DP を使うと、スマホで撮影した紙資料でも、段落構造・表構造を保持した HTML形式へと変換できます。詳細はfc_2025_upstage_handson:Step1をご覧ください。
コード
def upstage_document_parse(file_path: Annotated[str, Content]) -> str:
"""
📄 文書をHTMLに変換する関数
- Upstage Document AI API を利用
- ファイルを送信して OCR + HTML 化
"""
# Step 1. APIキーを環境変数から取得
api_key = os.environ.get("UPSTAGE_API_KEY")
if not api_key:
raise ValueError("❌ UPSTAGE_API_KEY が環境変数に設定されていません。")
# Step 2. 画像ファイルの読み込み
with open(file_path, 'rb') as file:
files = {
"document": (os.path.basename(file_path), file, "image/jpeg")
}
data = {
"model": "document-parse-nightly",
"ocr": "auto",
"output_formats": "html"
}
# Step 3. APIリクエスト送信
response = requests.post(
"https://api.upstage.ai/v1/document-ai/document-parse",
headers={"Authorization": f"Bearer {api_key}"},
files=files,
data=data
)
# Step 4. 結果をJSONで取得してHTML部分を返す
result = response.json()
return result.get("content", {}).get("html", "")
# ======================================================
# 📁 1. 学習・テスト用のサンプル文書パスを設定
# ======================================================
SAMPLE_DOCUMENTS = [
"./demo_imgs/check/TEST_IMAGE.jpeg",
]
part_1.md 2025-12-15
4 / 7
sample_file = SAMPLE_DOCUMENTS[0]
# ======================================================
# 🖼 2. HTML解析結果のプレビュー表示
# ======================================================
print("# 🖼 HTML解析結果のプレビュー表示")
display(HTML(html_result))入力(Before):スマホで撮影した清掃見積もり資料
- 2つの段落と複数の表が混在
- 照明や影が入った“実務でよくある紙文書”
- 一般的な OCRツールでは構造保持が難しいタイプ
出力(After):DPによるHTML構造化結果
DP に通すと、以下のようにLLMが理解しやすいHTML形式に自動変換されます。
- 段落構造が整理される
- 表(行・列)の構造がそのまま再現
- テキストと表が正しい順序で並ぶ“LLM Ready”な状態へ

3. Syn Pro の役割
Syn Proは、Upstage X KARAKURIが開発した 日本語特化の大規模言語モデル(LLM) です。日本語の文脈理解・文書処理タスクに最適化されており、DP(Document Parse)で構造化された文書と非常に相性が良いモデルです。
日本語特化の学習データで訓練されており、以下のようなタスクで高い性能を発揮します:
- 要約(Summarization)
- 情報抽出(Information Extraction)
- 質問対応(Classification)
- 業務文書の意図理解・項目推定(Question Answering)
(例)Syn Pro を用いた「文書タイプ説明」タスク
コード
def upstage_syn_pro(messages: list) -> str:
"""
🧠 LLMで応答を生成する関数
- Syn Pro モデルを使用
- messages には system / user ロールのプロンプトを含む
"""
# Step 1. APIキーを環境変数から取得
api_key = os.environ.get("UPSTAGE_API_KEY")
if not api_key:
raise ValueError("❌ UPSTAGE_API_KEY が環境変数に設定されていません。")
# Step 2. リクエストペイロードの構築
payload = {
part_1.md 2025-12-15
6 / 7
"model": "syn-pro", # "solar-pro2",
"messages": messages,
"temperature": 0.7,
"max_tokens": 16384,
# "reasoning_effort": "high",
}
# Step 3. APIリクエスト送信
response = requests.post(
"https://api.upstage.ai/v1/chat/completions",
headers={
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
},
json=payload
)
# Step 4. 応答メッセージ部分のみを抽出して返す
result = response.json()
return result["choices"][0]["message"]["content"]
# ======================================================
# 📝 Step 1 LLMに渡すプロンプトを定義
# ------------------------------------------------------
# - 文書全体をざっくりと要約して「どんな種類のドキュメントか」
# を LLM に説明させるためのプロンプト
# ======================================================
PROMPT = """
文書内容を見て、どんなドキュメントかを1-2文で簡潔に説明してください。
"""
# ======================================================
# 🧠 2. LLMに送信するメッセージの準備
# ------------------------------------------------------
# - userロールで HTML内容とプロンプトを一緒に渡す
# - HTMLは事前に upstage_document_parse() で取得済み
# ======================================================
explanation_messages = [
{
"role": "user",
"content": f"# ドキュメント内容(HTML):\n{html_result}\n\n# プロンプト指
示:\n{PROMPT}"
}
]
# ======================================================
# ☀3. Syn Pro による LLM 推論の実行
# ======================================================
print("\n🧠 LLMの答え:")
result = upstage_syn_pro(explanation_messages)
print(result)入力(Before):構造化された HTMLドキュメント
DP(Upstage Document Parse)で変換済みのHTMLをLLMに渡します。
- スマホ撮影した清掃見積もり資料を DP に通したHTML
- 2段落+複数表を含む「清掃見積もり概要ドキュメント」
- ドキュメント説明に関するPROMPT
# プロンプト(ドキュメント要約のための指示)
文書内容を見て、どんなドキュメントかを1-2文で簡潔に説明してください
出力(After):Syn Pro による文書内容の説明
このドキュメントは、建物清掃業務の見積金額を算定するための基準を示す資料です。
建物面積、機材使用、階数、作業日時、契約種別などに応じた基本料金、加算額、割引率を詳細に定めたもので、税抜・税込価格表や注意事項、事例を含む業界標準の料金体系を提供しています。
4. DP × Syn Pro で目指す世界観(まとめ)
DP は 「生のドキュメントを整える職人」、Syn Pro は 「整った文書から意味を読み取る日本語エンジン」 です。
紙・スキャンPDF → DPで構造化(LLM Ready) → Syn Proで要約・抽出・質問対応
という流れが、実務で使えるドキュメントAIの基本形になります。
次のPart 2では、この組み合わせを使った要約・抽出・質問の具体例と、Weave Traceによる処理の可視化をご紹介します。
実際に「動くパイプライン」を見て理解を深めていきましょう。



.png)
