
ここまで、Upstage DP x Syn Proを用いたドキュメント作業効率化シリーズ(with Weave)では以下をご紹介しました。
- Part 1 :DP と Syn Pro の役割・世界観を整理
- Part 2 :それらを使った 要約・抽出・質問対応+Weave Trace の可視化
今回のPart 3では、いよいよ事故状況報告書を題材に「システム連携前提の情報抽出パイプライン」を実装していきます。
さらに補助的に Weights & Biases WeaveのEvaluation機能を使い、パイプラインの評価や 精度確認の自動化も試していきます。
1. 実践パイプライン構築(事故状況報告書)

まずは、題材とする事故状況報告書の特徴を整理します。
- フリーフォーマットで書かれることが多く、文章構成に一貫性がない
- 本文・箇条書き・表・注意書きなど、複数の形式が混在する
こうした文書を整理するタスクには次のような課題があります。
- 多様なテンプレートに対応しつつ、一定以上の精度が求められる
- 保険会社や部署ごとにレイアウト・表現が微妙に異なる
- 「読む → 抜き出す → 定型フォーマットへ転記する」という人力の必要な作業
Part3では、この「人が毎回コツコツ行っている整理作業」をDP+Syn Proを用いてパイプライン化していきます。
2. 工夫ポイント
実務で使えるパイプラインにするため、次の観点を重視します。
▶ 必要な情報のみ抽出する
- 事故全体の要約ではなく、システム連携に必要な情報だけを狙って抽出
- 事故日時・場所・原因・再発防止策など、抽出項目の定義が重要
▶ 抽出項目の定義と正規化ルール
- 日付は YYYY/MM/DD
- 時間は 24 時間表記
- 情報がない場合は「記載無し」を入れる など
▶ Outputの制御(システム連携)
- JSONのキーやデータ型を事前に固定
- Downstreamシステムが加工無しで取り込める形式にする
3. パイプライン構築
ここから、実際にパイプラインを構築していきます。詳細はfc_2025_upstage_handson:Step2をご覧ください。
3.1 DP(Document Parse)
事故報告書(PDF / 画像)を HTMLに構造化します。このプロセスは、『Part1 > Upstage Document Parse (DP) の役割』のコードと同様です。
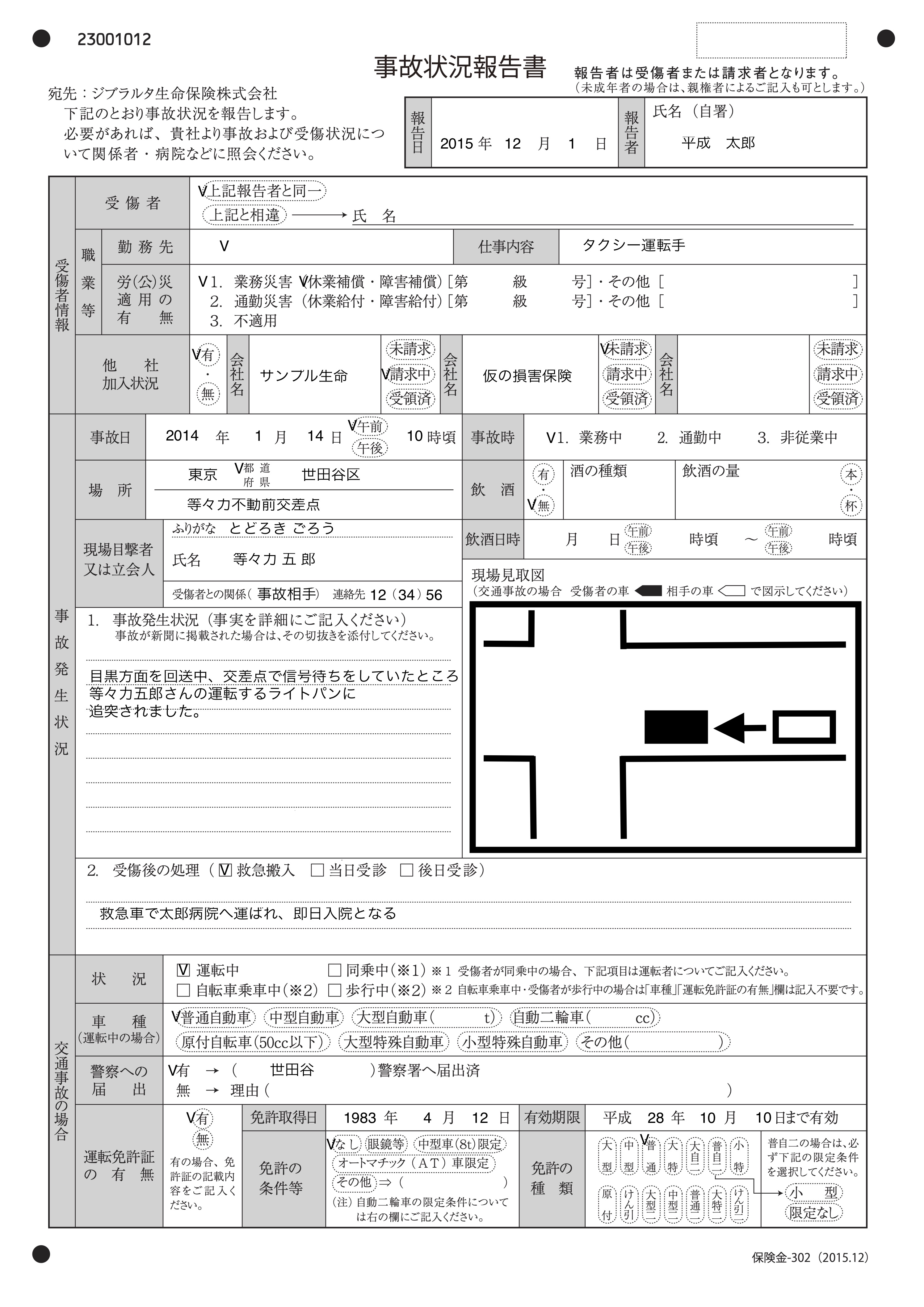
利用するサンプル画像は次のようなものです。
def upstage_document_parse(file_path: Annotated[str, Content]) -> str:
"""
📄 文書をHTMLに変換する関数
- Upstage Document AI API を利用
- ファイルを送信して OCR + HTML 化
"""
# Step 1. APIキーを環境変数から取得
api_key = os.environ.get("UPSTAGE_API_KEY")
if not api_key:
raise ValueError("❌ UPSTAGE_API_KEY が環境変数に設定されていません。")
# Step 2. 画像ファイルの読み込み
with open(file_path, 'rb') as file:
files = {
"document": (os.path.basename(file_path), file, "image/jpeg")
}
data = {
"model": "document-parse-nightly",
"ocr": "auto",
"output_formats": "html"
}
# Step 3. APIリクエスト送信
response = requests.post(
"https://api.upstage.ai/v1/document-ai/document-parse",
headers={"Authorization": f"Bearer {api_key}"},
files=files,
data=data
)
# Step 4. 結果をJSONで取得してHTML部分を返す
result = response.json()
return result.get("content", {}).get("html", "")
# ======================================================
# 📁 1. 学習・テスト用のサンプル文書パスを設定
# ======================================================
SAMPLE_DOCUMENTS = [
"./demo_imgs/information_extraction/_Himawari_Accident_Report.jpg",
]
sample_file = SAMPLE_DOCUMENTS[0]
# ======================================================
# 📄 2. Document Parse 実行
# ======================================================
print("\n📋 Document Parse:")
html_result = upstage_document_parse(sample_file)3.2 LLM(Syn Pro)+プロンプト設計
DPで構造化したHTMLをもとに、Syn Proが正しく情報を抽出できるよう、プロンプトを段階的に設計していきます。
最終的なゴールは、
DP → Syn Pro→ 整形 → JSON出力
という『システム連携可能な情報抽出パイプライン』です。
ここでは以下の3ステップに分けてプロンプトを設計します。
① 事故概要の要約(前処理)
LLMが読みやすいようにHTMLを整形し、必要な部分だけを取り出すための前処理ステップです。
・受傷者の情報
・受傷(事故)の情報
・免許証の情報
② 抽出項目の定義(スキーマ)
実務で必要となる項目を明確にし、さらに 正規化ルールをプロンプト内で指示します。
・日付 → YYYY/MM/DD
・時刻 → HH:mm
・推測はしない。なければ「記載無し」
・その他、日業務で必要な情報
③ 出力形式(JSON)の指定
出力形式を例としてLLMに明示します。こうすることでdownstreamシステムがそのまま利用できるようになります。
{
"受傷者名前": "山田 太郎",
"受傷者性別": "男",
"受傷者生年月日": "1990/05/12",
"受傷者住所": "福岡県福岡市中央区",
"受傷の日時/日付": "2025/10/10",
"受傷の日時/時間": "14:35",
# ... その他
}④ 実際に利用したプロンプト
# ======================================================
# 🪜 Step ① 情報抽出プロセスの段階的アプローチ
# ------------------------------------------------------
# - まずHTML内容を整形して、LLMが情報を取り出しやすい構造に変換
# - 抽出対象の情報は「受傷者の情報」「受傷(事故)の情報」「免許証の情報」
# ======================================================
PROMPT_1 = """
内容を変えずに、HTML内容を綺麗に整理して、新たなHTMLコードを作成してください。
- 必要な内容
- 受傷者の情報
- 受傷(事故)の情報
- 免許証の情報
"""
# ======================================================
# 🪜 Step ② 必要な情報の明確な定義
# ------------------------------------------------------
# - 実務で必要な情報を明示的に指示
# - 「記載無し」などの記載ルールや日付・時間フォーマットも指定
# - 不明確な推測を防ぐことで安定した抽出結果を得る
# ======================================================
PROMPT_2 = """
情報が明確に記載されていない場合は、「記載無し」 と記載してください。
不明確な推測は行わず、記載内容のみに基づいて抽出してください。
-「受傷者住所」は 番地を含めない
-「受傷の場所」は 番地を含める
- 日付は 西暦(YYYY/MM/DD) で表記する
-「受傷の原因」「受傷の内容」は抽出情報から分けて整理する
- 時刻は 24時間表記(HH:mm)
"""
# ======================================================
# 🪜 Step ③ 出力形式の定義
# ------------------------------------------------------
# - LLMに対して出力フォーマット(JSON形式)を明示
# - 事前に構造を定義しておくことで、システムとの連携が容易になる
# ======================================================
PROMPT_3 = """
ドキュメント内容を見て、以下のフォーマットに従って JSON形式で標準化された情報を出力する担当者です。
# 出力フォーマット/例(JSON形式)
{
"受傷者名前": "山田 太郎",
"受傷者性別": "男",
"受傷者生年月日": "1990/05/12",
"受傷者住所": "福岡県福岡市中央区",
"受傷の日時/日付": "2025/10/10",
"受傷の日時/時間": "14:35",
"受傷の場所": "福岡県福岡市博多区博多駅前3-4-5",
"受傷の原因": "通勤中に段差で転倒",
"受傷の内容": "右ひじ擦過傷",
"飲酒の有無": "無",
"警察の届出/有無": "有",
"警察の届出/警察署名": "福岡警察署",
"免許証番号": "123456789012",
"免許証種類": "原付",
"免許有効期間": "2027/05/12"
}
"""4. 結果の確認

完成したパイプラインに事故状況報告書を流し込むと、定義した仕様どおりにJSONが生成されます。
確認できるポイント:
- 異なるテンプレートにも柔軟に対応
- 正規化ルール(YYYY/MM/DD、24hなど)が適用されている
- 「記載無し」も適切に反映
- JSONのキーが設計通り
詳細はfc_2025_upstage_handson:All Resultsで確認できます。
5. 評価の必要性(Weave Evaluation)
自動化パイプライン構築の際 必要なのは、「抽出結果は本当に正しいのか?」の検証です。
Weave Evaluationを使うことで:
- 正解データとの比較
- スコアの可視化
- 改善前後の比較
- 評価設定や履歴の管理
といった作業を自動化・簡易化できます。
5.1 正解ラベルの準備
ラベルは最終的にシステムへ渡す『正解となる値』です。
後で説明する『前処理・モデルの定義』に合わせ、今回は以下のKeyを持つDictionaryを用意します。
- file_path, key, target
label = {
"受傷者名前": "サンプル 太郎",
"受傷者性別": "男",
"受傷者生年月日": "1970/04/03",
"受傷者住所": "記載無し",
"受傷の日時/日付": "2019/09/15",
"受傷の日時/時間": "15:00",
"受傷の場所": "東京都中央区京橋3-30-90",
"受傷の原因": "左脇道より一旦停止せずに出てきた相手方の小型トラックに衝突",
...
}
# ======================================================
# データセットの整形
# ------------------------------------------------------
# LLMの出力 result_json と正解データ label を比較するために、
# 各項目(キー)ごとに評価対象をフラットなリスト化する
# ======================================================
datasets = [
{
"file_path": sample_file,
"key": k,
"target": v
}
for k, v in label.items()
]上記処理により、以下の形でdatasetsが準備できます。
{
"file_path": "./demo_imgs/information_extraction/_Himawari_Accident_Report.jpg",
"key": "受傷者名前",
"target": "サンプル 太郎"
},
{
"file_path": "./demo_imgs/information_extraction/_Himawari_Accident_Report.jpg",
"key": "受傷者性別",
"target": "男"
},
...5.2 スコアラーの定義
正解ラベルデータとモデルの抽出結果を比較する『スコアラーを定義』する必要があります。
今回は、完全一致で評価するmatch_scorerを定義しますが、必要に応じてEmbedding類似度スコアも利用できます。
Embedding類似度を使うことで「自然言語の類似度の評価もできるので」詳細はfc_2025_upstage_handson:Step3 Plusをご覧ください。
# ======================================================
# スコアラーの定義
# ------------------------------------------------------
# - match_scorer :完全一致をチェック(主に数値・コード・短いテキスト向け)
# - EmbeddingSimilarityScorer :意味的な類似度をチェック(原因や内容などに有効)
# ======================================================
@weave.op()
def match_scorer(output: str, target: str) -> dict:
"""
📌 完全一致を判定するスコアラー
- 前後の空白を除去して文字列を比較
- 一致すれば correct=True
"""
correct = (str(output).strip() == str(target).strip())
return {"correct": correct}
scorers = [match_scorer]5.3 前処理定義
「5.1 正解ラベルの準備」で準備したデータセットの前処理コードを作成しました。
- イメージ読み込み
- DP実行
- Syn Proによる情報抽出
- 結果JSONのキャッシュ化
を行います。これにより、繰り返し作業であっても『追加コストを使わず』に情報抽出ができます。
# ======================================================
# 前処理定義
# ------------------------------------------------------
# - weave.Model に渡す前段階でデータを処理する関数
# - Document Parse & 情報抽出結果をキャッシュしておくことで
# 再実行時の処理を高速化
# ======================================================
@weave.op()
def inf_document(dataset):
"""文書を前処理して DP 結果をキャッシュする"""
# Init
file_path = dataset["file_path"]
key = dataset["key"]
target = dataset["target"]
# ファイル名のみ抽出
file_name = os.path.basename(file_path)
cache_path = os.path.join(CACHE_DIR, f"{file_name}.json")
# ✅ キャッシュのある場合 → 利用
if os.path.exists(cache_path):
with open(cache_path, "r", encoding="utf-8") as f:
result_json = json.load(f)
else:
# 🧠 キャッシュの無い場合 → 推論
result_json = process_document_pipeline(
file_path,
prompt1=PROMPT_1,
prompt2=PROMPT_2,
prompt3=PROMPT_3,
)
# 結果保存
with open(cache_path, "w", encoding="utf-8") as f:
json.dump(result_json, f, ensure_ascii=False, indent=2)
return {"ie_json": result_json, "key": key, "target": target}5.4 モデル定義と評価
前処理で、DP + Syn Proを用いた情報抽出が終わった状況なので、ここでは「Dictionaryから必要な推論結果を読んでくる」単純な作業を行います。
最終的に、評価(weave.Evaluation)タスクでは、
- 正解ラベルデータセット
- スコアラー
- 前処理モジュール
- 推論モデル
を Evaluation に渡すだけでテスト実行できます。
# ======================================================
# モデル定義
# ------------------------------------------------------
# weave.Modelを継承してpredictメソッドを実装
# 今回は Jsonから、必要情報をGETする
# ======================================================
class InformationExtractonModel(weave.Model):
@weave.op()
def predict(self, ie_json: str, key: str, target: str):
pred = ie_json.get(key)
return pred
model = InformationExtractonModel()
# ======================================================
# Evaluation設定
# ------------------------------------------------------
# OPENAI_API_KEYが設定されている場合のみ
# 意味類似スコアラーを追加で利用
# ======================================================
evaluation = weave.Evaluation(
dataset=datasets,
scorers=scorers,
preprocess_model_input=inf_document
)詳細はfc_2025_upstage_handson:Step3をご覧ください。
5.5 結果
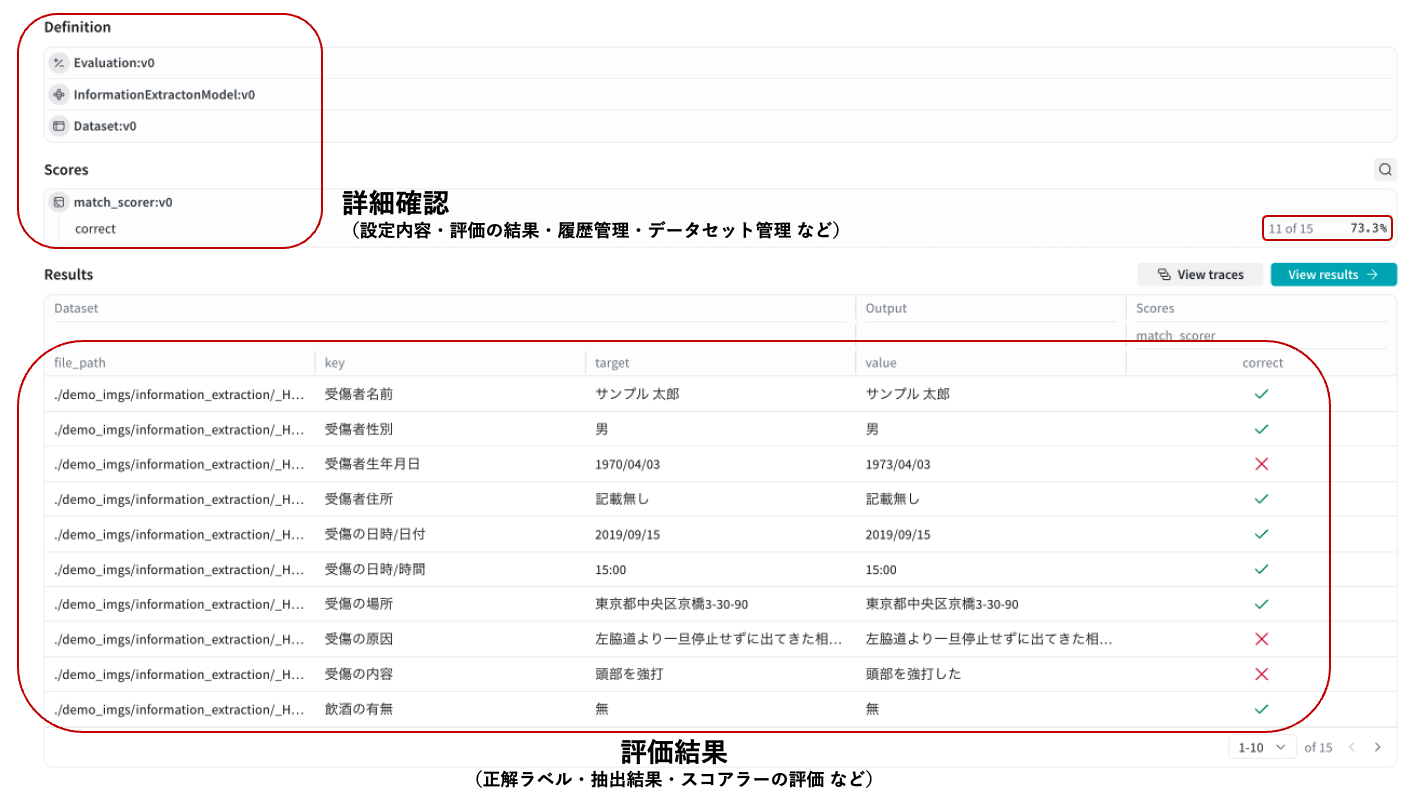
イメージは、weaveウェブ上の画面です。
Evaluation の UI 上では、
- 使用モデル
- データセット
- スコアラー
- 実行履歴
などが可視化され、評価の効果を確認できます。
実際パイプラインの精度を確認する際には、
- 大量データセットの確認
- モデルやデータセットの変更
- 精度構造のための様々な設定変更
などが頻繁に行われ、その履歴管理はとても大事です。
Weave Evaluationの機能をより活用することで
- モデル・詳細設定・データセットの履歴管理
- 評価結果の社内共有
- モデルの改善の工夫
などが、一気痛感で管理できるでしょう。
6. まとめ
Part3では『Upstage DP+Syn Proを活用した情報抽出パイプラインを構築』しました。
- DP:多様なテンプレートの事故状況報告書をOCR+構造化
- Syn Pro:段階的プロンプトで要約・情報抽出・JSON出力
- Weave:パイプライン評価の自動化と履歴管理
本稿で紹介する手法は一例ですが、応用次第で幅広い業務ドキュメントに活用することができるでしょう。
ぜひ皆さんも、この記事を参考に、ご自身の現場でのドキュメント作業を見直してみてください。
Related posts


導入初日からAI活用成果を実現!全てのお客様の非構造化データ(紙文書、PDF、手書き帳票、Excel等)をオンプレで活用:AIソリューション「SolarBox」について


